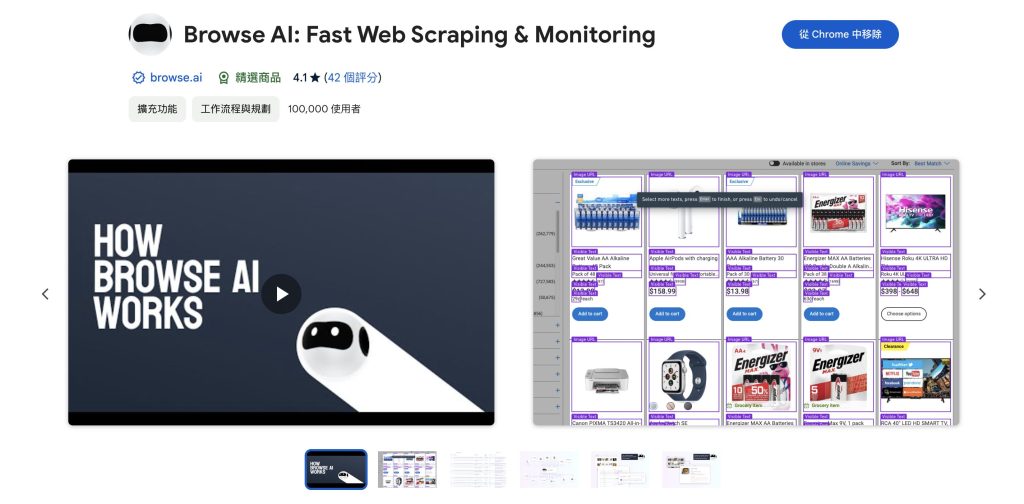
- 1.Browse AI:零程式碼抓取單一網址的網路爬蟲工具
- 2.Octoparse: 豐富的預設網路爬蟲資料庫
- 3.Web Scraper: 一次爬取多頁面的免費網路爬蟲工具
- 4.Data Miner: 套用及客製化公開網路爬蟲範本
網路爬蟲(Web Crawler)是一種可以自動從網站抓取資料的工具或程式。它的作用就像一個數位助理,按照你的設定自動瀏覽網頁,收集文字、圖片、表格、價格資訊等,並整理成 Excel、CSV 或其他方便分析的格式。
對於沒有程式背景的人來說,「零程式碼網路爬蟲工具」是一個非常實用的選擇。這類工具不需要寫程式碼,你只需透過簡單的操作介面就能完成資料抓取任務。無論是做市場調查、競爭分析、整理報告資料,甚至是個人研究,都能節省大量手動複製貼上的時間。
使用零程式碼爬蟲,你可以輕鬆做到:
- 自動抓取網站資料,免去繁瑣手動操作
- 收集文字、圖片、表格資訊,並直接整理成檔案
- 篩選特定資料,只保留你需要的資訊
- 定期監控網站更新,隨時掌握最新數據
簡單來說,即使你不是程式高手,也能靠零程式碼網路爬蟲工具,把「網站資料自動抓取」變得輕鬆可行。這不僅節省時間,也讓資料整理和分析工作更有效率。網路爬蟲程式可以將網頁上搜尋到的許多資料,輕鬆爬取並蒐集到檔案中,再進一步整理成實用的分析或資料。
許多人都會透過 python 爬蟲程式來獲取網路數據,但如果不會程式且需求較簡單,其實現在有許多不用寫程式的免費網路爬蟲工具可以使用,省下大量時間,讓你輕鬆複製貼上!
免費零程式碼網路爬蟲程式推薦
1.Browse AI:零程式碼抓取單一網址的網路爬蟲工具
- 使用方式:網頁版及Chrome 插件
- 方案:終身免費版且每月提供 50 個點數
- 付費版:按照點數數量提供付費級距
Browse AI 是一款線上免費網路爬蟲程式,提供網頁版及Chrome Extension版本。目前服務提供兩種主要功能「抓取有規律的網站資料」以及「監控網站頁面變化」,換句話說,主要針對「單一網址」的資料抓取。
除了自己製作一個全新的網路爬蟲機器人,更強大的是免費版就能使用 Browse AI 內建的「Prebuilt Robots」,在常見的平台上,預設了非常多實用情境,涵蓋豐富的主題網站,從 Linkedin、Pinterest、Tiktok、Google map 到 Booking.com 等等。
也不用擔心目前介面是英文,只要使用 Google 網頁翻譯就能輕鬆轉換為中文,對於重要的功能都能大概理解,非常方便!
更棒的是,目前免費版可終身每月獲得 50 個點數,代表你每月都能免費使用服務,而且只要一個點數就可以使用爬蟲功能,真的非常佛心!
如果你的使用需求明確且超過目前額度,想要使用付費版本,使用以下合作按鈕註冊就能獲得優惠
現正搭配年繳方案省20%更划算!
教學一:客製化網路爬蟲抓取有規律的網站資料
由於 Browse AI 是以網址作為資料搜集的單位,建議以分類頁、集合頁或是表格頁面為抓取頁面,例如台灣證券交易所成交資料等等。
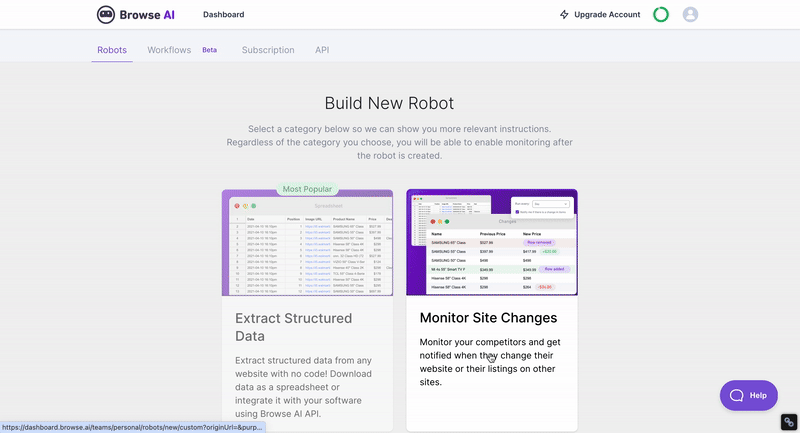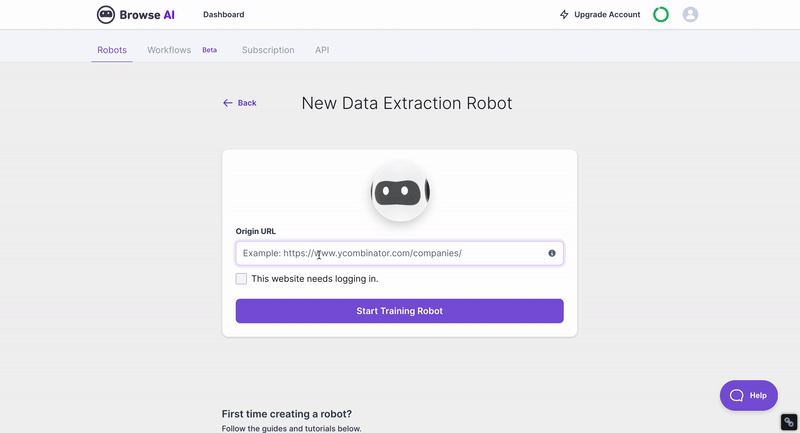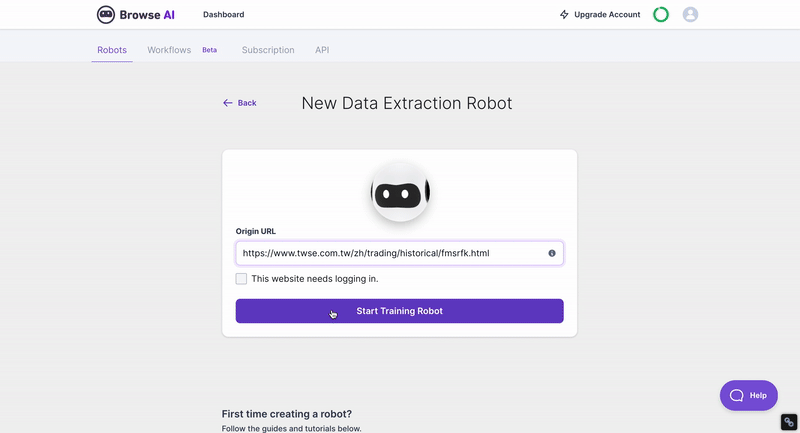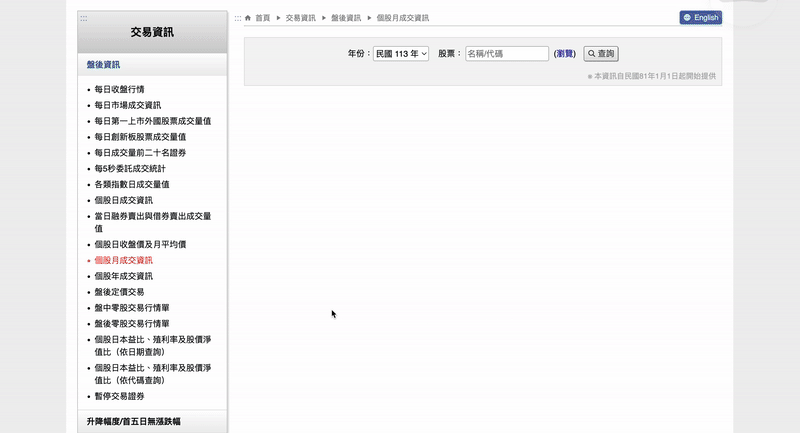
步驟一:登入後,點選「Robot」並選擇「Extract Structure Data」
步驟二:輸入網址並點選「Start Training Robots 」
步驟三:將想要抓取的資料錄製下來
步驟四:選擇抓取的資料數量後匯出即可獲得 excel 檔案
教學二:使用內建機器人監控網站頁面變化
另一個很方便的功能就是輸入網址並設定通知,以後網頁上有更新就能第一時間收到通知!
現正搭配年繳方案省20%更划算!
2.Octoparse:豐富的預設網路爬蟲資料庫
- 使用方式:軟體
- 方案:免費版無提供點數
- 付費版:付費版才可使用預先設定好的機器人
Octoparse 一樣是提供網路爬蟲功能的軟體,但是不提供客製化爬蟲或監控網頁的功能,使用者只能從已建立好的爬蟲資料庫中去搜尋,需要花費時間搜尋符合自己需求的爬蟲,但又不能針對抓取項目調整,較不方便!
好處是Octoparse 針對付費版本,可以無限使用部分已建立好的爬蟲資料庫,如果需求非常明確是要定期抓取電商網站資料做競爭者分析,或是 Youtube 頻道監控都非常適合!
3.Web Scraper:一次爬取多頁面的免費網路爬蟲工具
- 使用方式:網頁版及Chrome 插件
- 方案:七天免費試用版或是僅支援檔案下載到電腦的免費Chrome 插件版本
- 付費版:支援雲端儲存及爬取多種網頁架構
Web Scraper 最大的特色是「可一次爬取不同網址的資料」,支援龐大的資料量外,在操作上也較偏向專業使用者,相比其他工具透過視覺化點擊或選取就能完成設定,Web Scraper 的爬取設定步驟較適合理解網頁 html 架構的使用者。
一開始下載 chrome插件後,會不知道要怎麼操作,建議先觀看 Web Scraper 影片教學資源熟悉整體功能。要使用 Web Scraper 必須使用開發者介面,一層一層設定相應的爬取網址及指定內容。
最基本的使用步驟是打開Web Scraper 插件後,以mac 電腦為例,按照說明使用快捷鍵「Cmd+Opt+I 」打開開發者模式,接著找到 「Web Scraper」的頁面,接著先建立爬取的網址順序,再指定爬取的文字或圖片。
設定的過程較為複雜,但一次免費爬取多個頁面是市面上工具中少見的功能。
4.Data Miner:套用及客製化公開網路爬蟲範本
- 使用方式:網頁版及Chrome 插件
- 方案:不超過每月 500 頁抓取限制及可持續使用免費版
- 付費版:可解鎖更多頁面同時客製化網路爬蟲工具
Data Miner 最特別的是類似腳本的機制,你可以直接使用公開的網路爬蟲範本來爬取指定資料,甚至是編輯現有的模板來符合自己的資料抓取需求。
網路爬蟲設定的難度介於中間,雖然大部分是視覺化設定,但步驟相對較多,建議可以優先使用其他人已經製作的公開範本,再進行客製化修改較省時間。
雖然提供抓取超過一頁的機制,可惜的是目前似乎無法在瀑布流網站上自動進行更新,例如社群媒體,不過免費版本只要每月抓取數量不超過 500 頁,就可以一直保有免費資格,算是非常佛心又好用的方案!